|
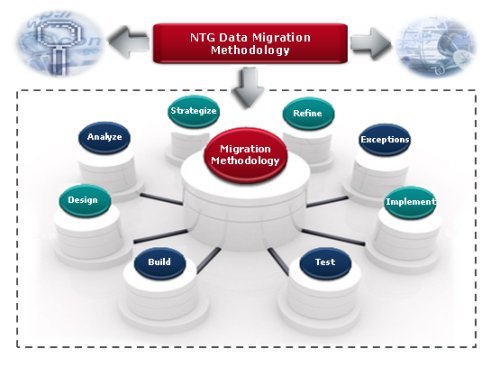
DESIGN
In the Design phase, we will be working through each data element from every source data structure, and deciding whether to migrate each element, and where it maps into the new structure.
This phase of data migration must advance in parallel with the analysis phase of the main project. This is true because each data element, identified as a candidate for migration, is likely to result in a change to the data model.
The Design phase is not intended to thoroughly identify the conversion rules by which old data will be converted to fit into the new system; rather, it is the act of making a list of the old data elements that we intend to migrate.
BUILD
The Build phase of migration must go in parallel with the design phase of the main project. The project team commences the building phase by generating the new data structures and creating them within the database.
It is necessary to perform data mapping to the physical data model as opposed to logical data models.
With the physical data structures in place, the project team can begin the mapping process.
A team of at least three people from each core business area generally conducts the mapping process. Each team should be composed of:
- Business analyst, ideally an end user possessing intimate knowledge of the old data to be migrated.
- Systems analyst with knowledge of both the old and new systems.
- Systems engineer who performs data research and develops migration programs and scripts based upon the mappings defined jointly by the business analyst and the systems analyst.
During this phase, the actual data migration code is developed, or the scripts written if a specific data migration tool was chosen.
During this phase the following issues are addressed:
- Resolving data incompatibilities, irregularities and exceptions during conversions. The tool should be able to produce data irregularities and integrity violations reports. The source data will need to be cleansed by the end users or the legacy system administrators.
- Maximizing code efficiency by taking full advantage of parallelism and performance tuning. The
timeframe for the migration can be quite tight.
TEST
The Testing phase deals with two main subject areas: logical errors and physical errors.
Physical errors are syntactical in nature and can be straightforwardly identified and corrected.
Physical errors do not mean that there were errors in the mapping process. Rather, it deals with errors in applying rules of the scripting language used in the conversion process.
Running the data into the scripts is where we identify and resolve logical errors.
The first step is to execute the mapping. Even if the mapping is completed successfully, we must still identify:
- The number of records this script is expected to create.
- Whether or not the correct number of records got created. And resolve any discrepancies.
- Whether or not the data got loaded into the correct fields.
- Whether or not the data was correctly formatted.
The most effective test of data mapping is providing the newly loaded databases to the users who were involved in the analysis and Designing of the core system. Quite often these users will begin to identify other old data elements that should be migrated, and which were not identified during the analysis and design phases.
Data mapping often does not make sense to many end users until they can physically interact with the newly loaded databases. Most likely, this is where the majority of conversion and mapping requirements will be identified. Most people do not realize that they have overlooked something until it is not there anymore. For this reason, it is extremely important to unleash the end users upon the newly loaded data bases sooner rather than later.
The data-migration testing phase must be reached as early as possible to guarantee that it takes place prior to the Designing and building phases of the main core project. Otherwise, months of development effort can be wasted since each newly identified migration requirement affects the data model. This, in turn, call for painful amendments to the applications built upon the data model.
REFINE
The Refinement phase is where data cleansing is managed. Each modification to the data model, adjustment to the conversion rules, and changes to the scripts are basically combined to form the Refinement phase.
Scripting may cover all of the data cleansing situations, however, a certain degree of manual data cleansing may be required. It is the user community who can effectively complete this manual task.
It is important to know that the Testing step, and the Refinement step will be reiterative. Expect to go several times through these two steps before the data can be declared completely clean.
At this point, it is essential that both the logical and the physical data models be maintained
concurrently. One has to recognise that this will double the administrative workload for the keeper of the data models. One must maintain continuity between the logical and physical designs.
Tools can be used to maintain the relationship between the logical and physical models, although this
will require several in-house reports to be developed. For example, the project team will want reports that indicate discrepancies between entities/tables and attributes/columns. These reports will highlight any mismatch between the number of entities versus tables, and attributes versus columns. These reports should also identify any naming convention violations and point out any data definition discrepancies. It is prudent to select a tool that provides an API (Application Program Interface) to the meta-data. This will definitely be needed.
|